Lesson number one that AI developers learn is that any AI system is only as good as the dataset it is trained on. Article written by Tyler Baker VP, Engineering (Qualcomm Innovation Center)- a Foundries.io team member
That’s why a lot of the effort ploughed into the development of edge AI systems is devoted to curating the training dataset, so that it provides sufficient depth to enable effective learning for the intended use case, but without creating such a large model that a viable edge device cannot run it.
Today, this training dataset is normally general: a model for recognising cats visually is trained on tagged pictures of cats drawn from the global internet archive of cat images. A device manufacturer would not go to the locations where its catspotting device is going to be deployed and take millions of images of the local cats in the local lighting conditions.
This approach to AI model training is the developer’s best effort at preparing the device to understand its operating environment. It is fine for cat spotting. But in many applications of AI at the edge, this type of universal training dataset fails to provide the device with the knowledge it needs to handle specific local conditions.
Take the example of an autonomous weeding robot for farms. The robot’s camera will be programmed to recognise images of leaves, to distinguish between crop plants and weeds and to treat different weeds appropriately. To minimise the size of the weed recognition model, the developer will train it on images of the weeds most commonly encountered by growers, rather than a database of all the world’s plants. This limited model is then programmed into all the weeding robots that are shipped to farmers.
This might work well until a previously unknown weed starts to appear in the farmers’ fields, perhaps an invasive species imported from overseas. Or, what if a local group of farmers breed a new hybrid variety of a crop which looks subtly different from the crop plants on which the model was trained? In this case, the robot might leave a weed to thrive while killing the fresh shoots of the crop plant.
The same can apply elsewhere. In the field of medicine, personal health monitoring models might be trained on data from people recruited for testing, who may be cash-poor and time-rich: for example, university students and other young people. The patients who benefit most from using an AI health device might be the older generation. In this case, the patterns of physiological data that the device is tracking might not match well the profile of the typical user.
So how to solve the problem of the general training dataset?
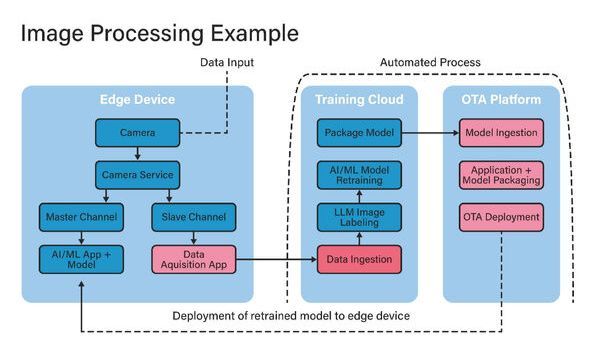
The answer might lie in instituting a continuous feedback loop between the training dataset, the model development system in the cloud and the data captured locally by the installed base of devices in the field (see Figure 1). The inspiration for this new approach under development by embedded software specialists Foundries. io and Edge Impulse is the continuous integration/continuous development (CI/CD) model of software deployment.
In this approach, the data (images in the smart farming example, physiological data for a health monitoring product) captured locally by the edge device would be used not only to feed the inference engine, but also, in parallel, would be collected by a data acquisition process and fed back to the training dataset in the cloud. The model would be trained on the newly augmented or refined dataset, a new inferencing algorithm would be generated and that algorithm would be deployed back to devices in the field, closing the feedback loop. By using data drawn from a device’s individual environment, the developer would be able to achieve improvements in the performance and accuracy of the model.
For electronics updates please visit: https://efemag.co.uk/category/news/




{kind=link}